
Automating CI/CD with GitHub Actions Marketplace
Streamline Development with Community-Driven Automation


For most data teams, the code that powers pipelines, transformations, and analytics dashboards isn’t just SQL scripts or Python notebooks—it’s an evolving, production-grade software system. And like any serious software system, it benefits from continuous integration and continuous delivery (CI/CD). The catch? Standing up a bespoke CI/CD pipeline from scratch can feel like a yak-shaving exercise, especially for teams that don’t want to become part-time DevOps engineers.
This is where the GitHub Actions Marketplace becomes a force multiplier. Instead of writing the entire automation logic yourself, you can leverage pre-built workflows, created and maintained by the community and trusted vendors, to integrate testing, linting, deployment, and monitoring into your repository with minimal overhead. Think of it as importing a tested, production-ready function into your analytics codebase rather than reinventing it line by line.
Why GitHub Actions Marketplace Fits Data Teams
Data engineering and analytics codebases often combine multiple languages and tools—SQL for transformations, Python for orchestration or ML, YAML for configuration, shell scripts for ETL glue, and even Java or Scala for Spark-based processing. The heterogeneity makes automation more challenging than in a single-language codebase. But GitHub Actions’ modular architecture lets you compose automation steps like building blocks, and the Marketplace gives you a library of ready-to-use building blocks for almost any need.
When working in the data space, you might already have CI/CD in mind for things like dbt model testing, schema validation, or automated data quality checks. Marketplace workflows extend that to code quality, dependency scanning, and security checks without requiring you to learn an entirely new automation framework.
Demo: Using Super-Linter
Let’s make this concrete with Super-Linter, a popular GitHub Action that aggregates dozens of linters for multiple languages into a single, configurable workflow. For a typical data platform repository, you might have:
Python scripts for ingestion and orchestration.
SQL for transformations and warehouse queries.
YAML for Airflow DAG configurations.
Markdown for documentation.
The Marketplace UI makes adding Super-Linter straightforward. You search for it in the GitHub Actions Marketplace, select the official action, and copy the provided YAML snippet into your repository’s .github/workflows/ directory.
The original yaml file created by the community is as below. We can edit it in the way we want to integrate into our workflows. I will keep it as it is and use it directly with synthetic files I created.
---
name: Lint
on: # yamllint disable-line rule:truthy
push: null
pull_request: null
permissions: {}
jobs:
build:
name: Lint
runs-on: ubuntu-latest
permissions:
contents: read
packages: read
# To report GitHub Actions status checks
statuses: write
steps:
- name: Checkout code
uses: actions/checkout@v4
with:
# super-linter needs the full git history to get the
# list of files that changed across commits
fetch-depth: 0
- name: Super-linter
uses: super-linter/super-linter@v8.0.0 # x-release-please-version
env:
# To report GitHub Actions status checks
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}This file tells GitHub to trigger the linting workflow every time someone pushes code or opens a pull request. It checks out the repository and runs the Super-Linter across all files it supports, using sensible defaults. The VALIDATE_ALL_CODEBASE flag ensures that even untouched files are linted—helpful when you want to enforce standards retroactively.
Below I created three different files with an order of Python, SQL, and dbt-oriented-SQL files;
import os, sys # unused imports and bad spacing
def get_sum( a,b ):
return a +b # inconsistent spacing
print(get_sum(2 , 3))SELECT id, name, Age
FROM customers
where age>18 and Country='USA'
order by name asc{{ config(
materialized='table',
unique_key='id'
) }}
SELECT
id,
name,
created_at,
sum(order_value) total_value -- missing alias AS and inconsistent spacing
FROM {{ ref('orders') }}
where created_at >= '2024-01-01'
group by id, name, created_at
order by total_value descI will run the Super-Linter against these files and check the output accordingly.
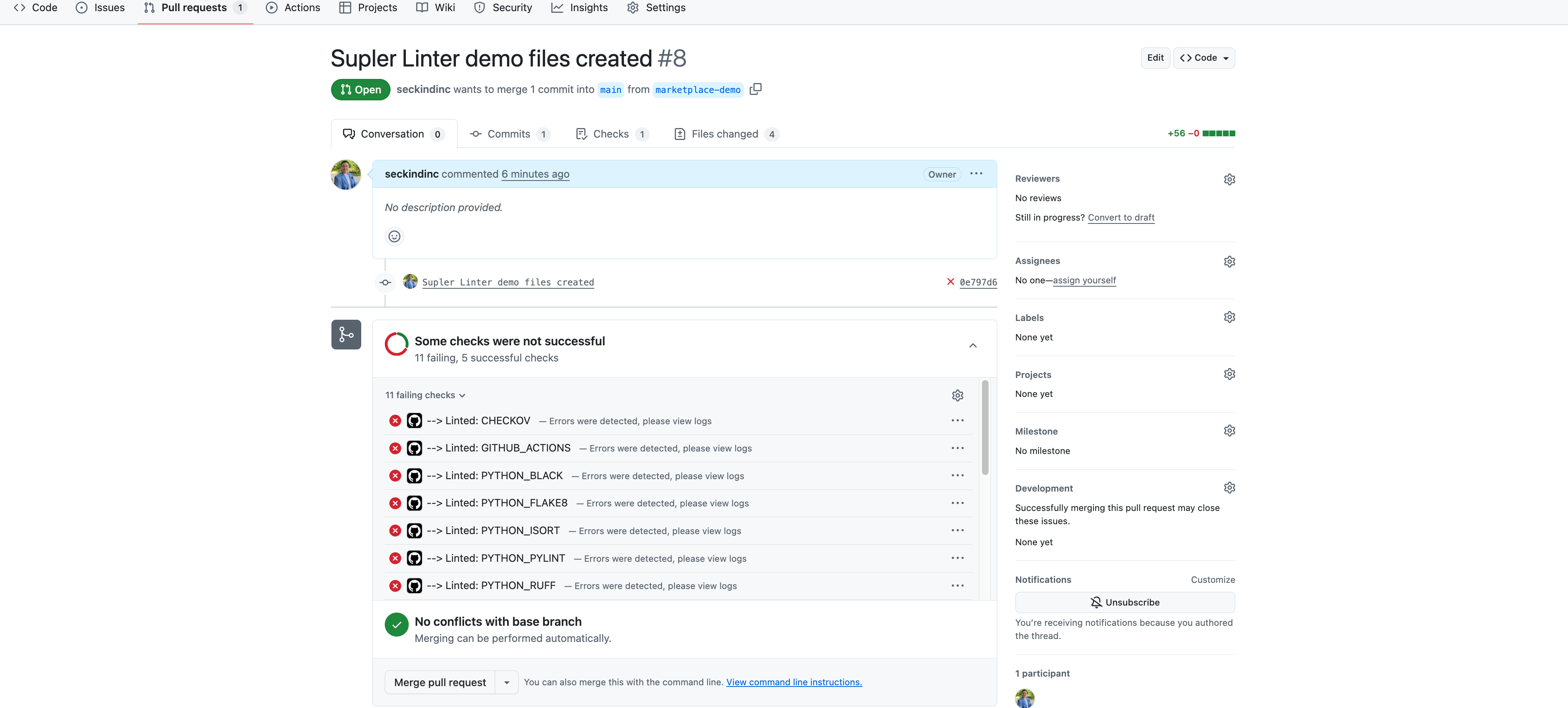
We have several issues as highlighted with the image above. If we want to go in details for a proper debugging, we can navigate to the Checks sections.
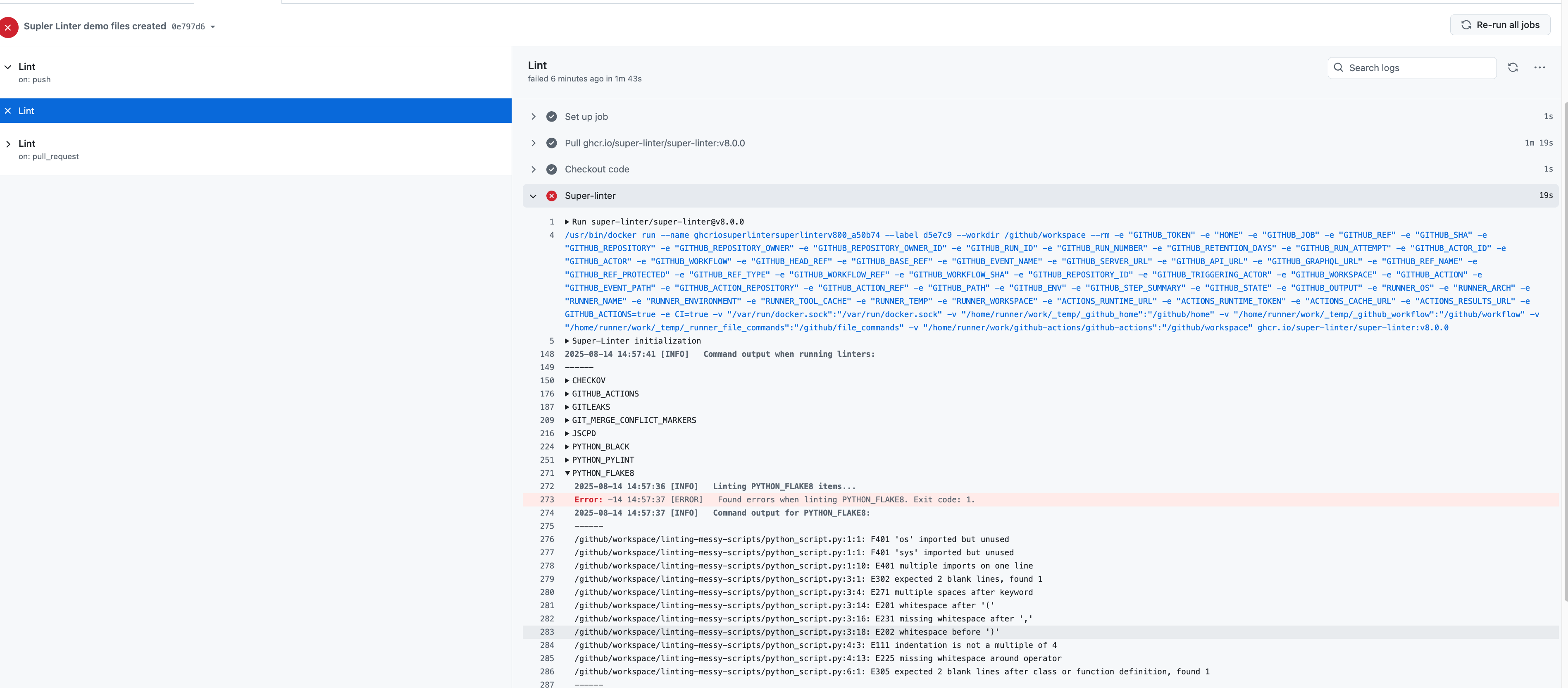
We successfully failed to pass the linting and styling tests that were pre-built through the Super-Linter action.
Why This Matters for Data Pipelines
In many data workflows, subtle syntax issues or configuration errors can cause silent failures—think a SQL join that accidentally becomes a cartesian product, a Python import that fails in production but works locally, or a malformed YAML file that breaks an entire orchestration DAG. Traditional testing can catch some of these, but linters give you a much earlier feedback loop.
By embedding Super-Linter in your CI pipeline, you enforce standards on every commit. That means a PR introducing an invalid SQL alias or a Python syntax error never even gets merged. In high-change environments—like a data engineering team rapidly iterating on ETL code—this is the kind of guardrail that keeps production stable without slowing down development velocity.
Extending the Workflow
Super-Linter is just one example. From the same Marketplace, you can find workflows to automatically test dbt models, validate JSON/YAML schema files, scan for secrets, build Docker images, deploy to Kubernetes clusters, or trigger downstream jobs in Airflow or Prefect. Because Actions are composable, you can chain multiple Marketplace steps together in a single .yml file, effectively stitching a CI/CD pipeline from pre-tested building blocks.
For teams running analytics workloads on cloud warehouses like Snowflake or BigQuery, it’s even possible to include deployment actions that apply schema migrations or refresh materialized views as part of the pipeline—turning your Git repo into the single source of truth for both code and its execution state.
Conclusion
Using pre-built workflows from the GitHub Actions Marketplace is not about outsourcing control—it’s about accelerating time-to-value while maintaining engineering discipline. For a data team, this means you can keep your attention where it belongs: on delivering reliable, insightful data products. Instead of losing days to hand-rolling CI scripts, you plug in vetted, community-maintained modules and start enforcing quality from day one.
CI/CD is no longer just a DevOps concern. In modern data engineering, it’s the backbone of delivering trustworthy, production-ready analytics at scale. The Marketplace puts that backbone within reach, without demanding a detour into full-time pipeline engineering. And with tools like Super-Linter, you can raise the quality bar across multiple languages and frameworks in one go—making your data codebase as robust as the insights it generates.